
dev/null robots
Wenn man mit statischen robots.txt Dateien arbeitet, kann man ohne weiters die allgemeine Anleitung für robots.txt in Multidomain heranziehen. Wesentlich komfortabler kann man es aber auch direkt über das Typo3 Backend haben.
Voraussetzungen/Installation
Die Extensions können direkt über den Extensionmanager aus dem TER installiert werden. Cooluri oder Realurl sind nach der Installation entsprechend zu konfigurieren.
Konfiguration spezifischer Robots
Die Konfiguration spezifischer Robots is nicht zwingend erforderlich, aber möglich. Um spezifische Robots konfigurieren zu können fürgt man am besten in einem System Folder pro Robot einen Eintrag vom Typ „Crawler config“ ein.
Dieser Eintrag bietet zwei Eingabefelder:
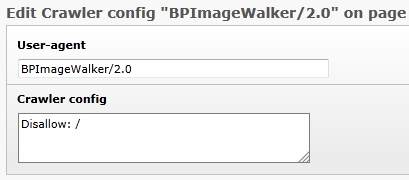
Konfiguration der Domain
Die Konfiguration der Domain beinhaltet die Aufnahme allfälliger spezifischer Robots, sowie eventuell eine vom Typoscript Template Basiskonfiguration.
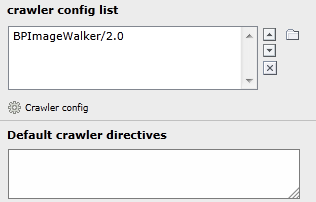
Konfiguration URL-Rewriting
Um das generierte robots.txt auch wirklich mit www.yourdomain.tld/robots.txt aufrufbar zu machen, ist ein Umschreiben (URL-Rewriting) erforderlich.
Cooluri
Bei Cooluri ist pro Domain ein Link zu konfigurieren. Dies geschieht im Backend in den Admin Tools von Cooluri.
Die verdefinierte typenum von dev/null robots ist 1964. Diese kann über das Typoscript Template auch pro Domain geändert werden. Änderungen des Default Wertes sind entsprechend. zu berücksichtigen. Der Parameter id entspricht jeweils der Startseite der Domain.
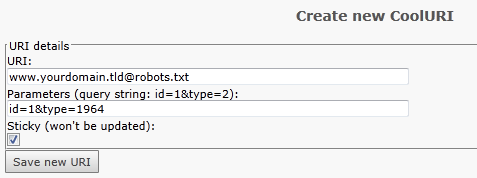
Realurl
Keine Beispielkonfiguration verfügbar.
.htaccess
Nicht empfohlen.
Robots Meta Tag
Zusätzlich oder auch alternativ kann ein Robots Meta Tag für die Seiten definiert werden. Das Verhalten hierzu kann über den „Constants Editor“ vordefiniert werden.
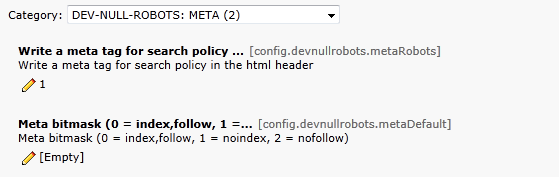
Innerhalb der Seite kann die Einschränkung für die Suchmaschinen Crawler festgelegt werden, welche sodann als Meta Tag ausgegeben wird.
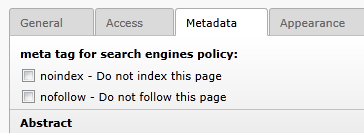
Die Einschränkungen aus der Seite und dem Typo Script Setup werden verknüpft. Dies bedeutet, daß eine Einschränkung aus dem Setup Template für alle Seiten gilt. Eine Einschränkung, welche über eine Seite festgelegt wird, wird nicht weitervererbt.
Beispiel
<meta name="robots" content="index,follow" />Wichtig
Derzeit erfolgt keine Abgleich bzw keine Überprüfung zwischen den einzelnen Crawler Konfigurationen und den Meta Tags.
Typoscript Template
Im Extensiontemplate der Domain kann ebenfalls eine einfache Konfiguration zur Verfügung.Im Constant Editor stehen zwei Optionen zur Verfügung.
Mit der ersten Option kann eine Default-Konfiguration ausgewählt werden. Diese Option hat keinen Effekt, wenn im Domain-Record eine Default-Konfiguration angegeben wurde.
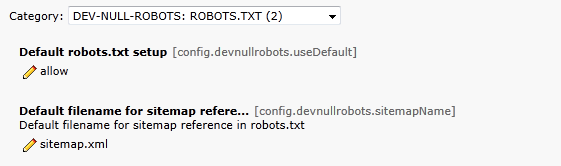
Die zweite Option dient zum Ändern der TypeNum zu robots.txt. Dies ist nur erforderlich, wenn bei der vorgegebenen TypeNum ein Konflikt mit einer anderen Extension auftritt.
